My vanity website reads various RSS feeds, displaying a preview of their content. I use HTML::TokeParser to break apart the HTML inside the RSS feed. One RSS feed is from my sports BLOG, but a recent change (the BLOG moved from one site to another) started causing the preview text to be blank.
What I should be seeing is:
Title Story 1
This is some preview text for the first story.
Title Story 2
This is some preview text for the second story.
Instead, I was seeing:
Title Story 1
Title Story 2
Below is an image from my website that shows the problem.
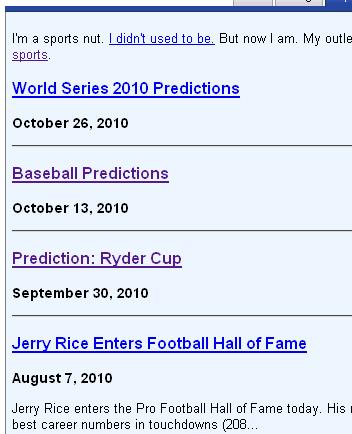
Where is the text under the first three stories?
Clearly HTML::TokeParser was working for some of the inputs. Here is the code that I use to retrieve the text from the RSS description element:
my $text = $text_stream->get_phrase();
I'm using get_phrase() to get the text. The documentation for get_phrase() says "This will return all text found at the current position ignoring any phrasal-level tags. Text is extracted until the first non phrasal-level tag."
Something must be different in the HTML entries of my RSS items. For the entries producing blank preview text, I saw this:
The characters before "The Giants" is the paragraph HTML element (<p>), written out with entities.
For the entries producing correct preview text, I saw this:
Notice that there is no paragraph element! That would turn out to be a big difference. In the HTML::TokeParser documentation, I read some guidance on identifying non phrasal-level tags: "The definition of phrasal-level tags is obtained from the HTML::Tagset module."
I look inside HTML::Tagset, and find this:
span abbr acronym q sub sup
cite code em kbd samp strong var dfn strike
b i u s tt small big
a img br
wbr nobr blink
font basefont bdo
spacer embed noembed
); # had: center, hr, table
The get_phrase() function basically stops when it finds an HTML tag that is not a phrase, and the paragraph element (<p>) is not a phrasal tag! To test this understanding, I modify the code slightly:
my $tok_ary = $text_stream->get_token();
print "\tTOKEN ARRAY 0: @{$tok_ary}[0]\n" if $opt_debug;
my $text = $text_stream->get_phrase();
What I saw is that for the items that did produce a good preview text, the debug output produced "T", but for the items that caused the problem, the debug output produced "S". "T" stands for "text", and "S" stands for "start (of tag)".
I then observed that the code change above began producing correct preview text! By writing this test, I managed to fix it! How? get_token() consumes the token! (I also observed that this test broke the preview text for the items that were originally working.) Given all these observations, I wound up using this as the fix:
my $tok_ary = $text_stream->get_token();
if (@{$tok_ary}[0] eq "T") {
$text_stream->unget_token($tok_ary);
}
my $text = $text_stream->get_phrase();
This change basically consumes the first token unless it's a piece of text, in which case it "ungets" the token. With this change, previews began appearing properly:
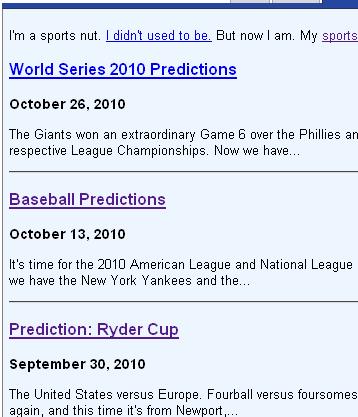
Solving this little problem relies on a few key practices that I try to follow. Number one: read and think about what exactly the documentation is saying. In this case, I had to resort to some source code, but the key is to read the available documentation for whatever library or system you're using, and think about it. Number two: make small changes to test your understanding. In this case, just the one small change proved to be enough!